Varianssianalyysi - SPSS-harjoitus 1
Jos olet ensimmäistä kertaa aloittamassa SPSS-harjoitusta, on ennen varsinaisen harjoituksen tekemistä syytä tutustua opiskeluohjeisiin.
Tässä harjoituksessa käytetään vuoden 2017 European Values Study -tutkimuksen Suomen osa-aineistoa, osaEVS.
Havaintoaineiston hakemisesta SPSS-ohjelmaan on erilliset ohjeet.
Varianssianalyysi

Varianssianalyysissa tutkitaan laatueroasteikollisten selittävien muuttujien ja mitta-asteikollisen selitettävän muuttujan keskinäistä riippuvuutta. Yleensä tehdään seuraavat oletukset:
- vertailtavat ryhmät ovat toisistaan riippumattomat eli tilastoyksiköiden tulokset eivät vaikuta toisiinsa (samassa satunnaisotoksessa ryhmät ovat yleensä riippumattomia)
- otoskeskiarvot ovat likimain normaalijakautuneet (suurilla otoksilla tämä ei yleensä muodostu ongelmaksi)
- varianssit ovat yhtä suuret (tämä tarkistetaan alla olevassa harjoituksessa Levenen testillä)
Yksisuuntainen varianssianalyysi
Usean keskiarvon yhtäsuuruutta voidaan testata yksisuuntaisen varianssianalyysin avulla. Malli voidaan kirjoittaa kahdella tavalla.
Vaikutusten mallina kirjoitettuna se on
missä y \( y \) on selitettävä muuttuja, m \( m \) yleiskeskiarvo ja a(i) \( a_i \) luokittelevan muuttujan i:nnen luokan vaikutus muuttujan y \( y \) keskiarvoon. Vaihtoehtoisena hypoteesina on, että ainakin jokin niistä poikkeaa nollasta. Nollahypoteesi testataan F-testillä, joka kahden ryhmän tapauksessa antaa täsmälleen saman tuloksen kuin yhtä suurien varianssien t-testi (riippumattomat otokset).
Keskiarvojen mallina kirjoitettuna malli on
Vaihtoehtoisena hypoteesina on nyt se, että ainakin jokin keskiarvoista poikkeaa toisista. Tavallista F-testiä käytettäessä joudutaan olettamaan havaintovirheiden varianssit yhtäsuuriksi. Viimeksi mainitusta oletuksesta voidaan hieman tinkiä, jos käytetään Brownin ja Forsythen tai Welchin testiä, jotka sallivat erisuuret ryhmittäiset varianssit.
Seuraavassa esimerkissä tutkitaan suomalaisten suhtautumista tuloerojen pienentämiseen tai niiden kasvattamiseen yksisuuntaisella varianssianalyysillä. Kyselyssä pyydettiin vastaajia kertomaan mielipiteensä jatkumolla 1–10, jossa pienet arvot kuvastivat vastaajan halua tasata tuloeroja pienemmäksi ja suuret arvot vastaajan halua lisätä kannustimia yksilön ponnistuksille (muuttuja q32d). Asteikon ääripäitä kuvaavat tekstit olivat 1= "tulotaso pitäisi saada tasaisemmaksi" ja 10= "yksilön ponnistuksille pitäisi olla suurempia kannustimia".
Selittävänä muuttujana esimerkissä on vastaajan perheen tulotaso (q98). Vaihtoehtoina muuttujassa oli kymmenen eri tuloluokkaa.
Ennen varianssianalyysin suorittamista selitettävästä muuttujasta (q32d) koodataan arvot 88 'En osaa sanoa' ja 99 'Ei vastausta' puuttuvaksi tiedoksi. Nämä arvot vaikuttaisivat oleellisesti ryhmäkeskiarvoihin ja täten vääristäisivät tuloksia. Selittävän muuttujan (q98) kymmenen luokkaa on järkevää koodata uudelleen vaikkapa viiteen luokkaan tarkastelun helpottamiseksi. Tehdään siis recode-komennolla uusi muuttuja tulot 'Kotitalouden tulotaso', jossa alkuperäisen muuttujan luokat A ja B saavat arvon yksi (Matala), C ja D arvon kaksi (Melko matala), E ja F arvon kolme (Keskitaso) ja niin edelleen. Samalla vaihtoehdot 88 'En osaa sanoa' ja 99 'Ei vastausta' määritellään puuttuvaksi tiedoksi. (Ks. tarvittaessa muuttujien uudelleenkoodausta käsittelevät harjoitukset.)
SPSS ohjelmistossa yksisuuntainen varianssianalyysi aloitetaan valikosta Analyze - Compare Means - One-Way ANOVA...
Seuraavassa ikkunassa valitaan selitettävät muuttujat (Dependent list) ja selittävä muuttuja (Factor).
Options-valikosta lisäämme Descriptive-valinnan, jolla saamme tulostukseen taulukon kuvailevista tunnusluvuista. Homogeneity of variance test -valinnalla testataan varianssien yhtäsuuruutta
Klikkaamalla Continue ja OK, saamme tulokseksi yksinkertaisen varianssianalyysin tulokset.
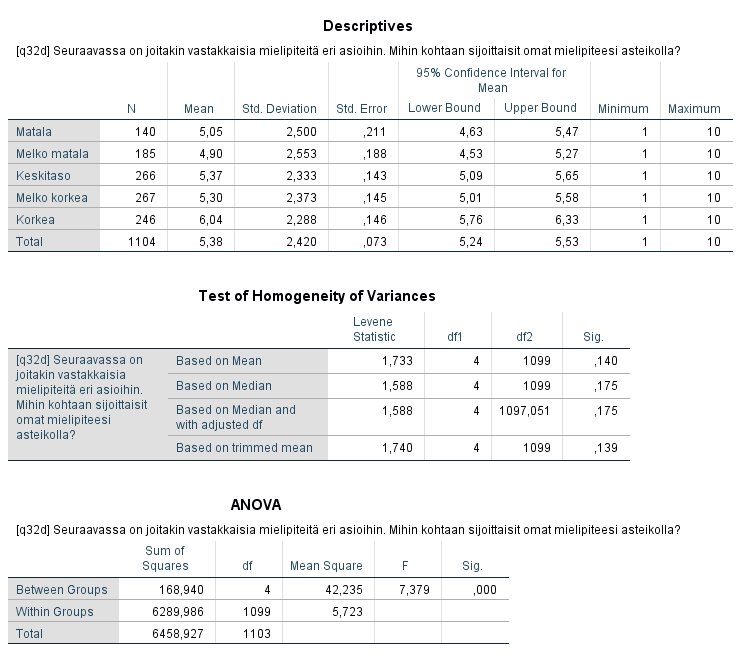
Taulusta Descriptives nähdään mm. ryhmittäiset jakaumat (N), keskiarvot (Mean), keskihajonnat (Std. Deviation) ja keskiarvojen keskivirheet (Std. Error).
Tauluun Test of Homogeneity of Variances saadaan varianssien yhtäsuuruustesti. Testi osoittaa, että nollahypoteesi jää voimaan eli ryhmittäiset varianssit ovat yhtä suuria, joten keskiarvotestin oletus yhtä suurista ryhmävariansseista on voimassa.
Taulun Anova F-testiluku (7,379) ja siihen liittyvä p-arvo (Sig.) kuvaavat ryhmien välisten erojen tilastollista merkitsevyyttä. Koska p-arvo on pienempi kuin yleisesti raja-arvona pidetty 0,05, voidaan nollahypoteesi ryhmäkeskiarvojen samansuuruisuudesta hylätä. Toisin sanoen eri kotitalouden tuloluokkiin kuuluvien välillä on eroja suhtautumisessa tuloeroihin. Tämän perusteella ei voida kuitenkaan vielä sanoa, mitkä ryhmät poikkeavat toisistaan tilastollisesti merkitsevästi.
Lisäämällä One-Way ANOVA -valikon Post Hoc -painikkeen kautta parittaiset vertailutestit saamme testattua, mitkä ryhmistä poikkeavat toisistaan tilastollisesti merkitsevästi. Parittaisia vertailutestejä on useita erilaisia ja niiden laskentatavat vaihtelevat. Usein käytettyjä ovat esimerkiksi Tukey ja Bonferroni. Valitsimme tässä esimerkissä Bonferroni-testin. SPSS ehdottaa oletuksena merkitsevyystasoa 0,05. Voit tarvittaessa muuttaa sen pienemmäksi.
Paina Continue ja OK. Ohjelma tulostaa vertailutestit.
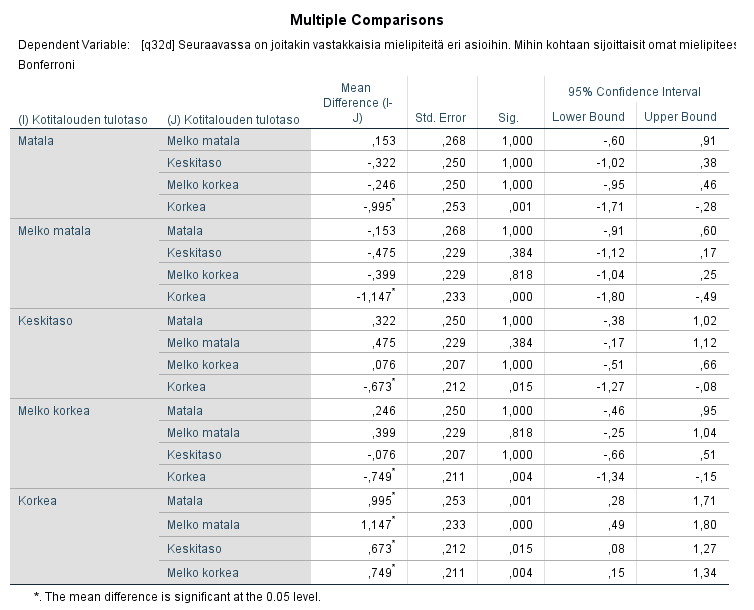
Testeissä verrataan siis kunkin ryhmän keskiarvoa erikseen kaikkiin muihin. Parivertailun perusteella tilastollisesti merkitsevä ero keskiarvoissa on ainoastaan korkean tuloluokan ja muiden tuloluokkien välillä. Tulosten perusteella korkeimpaan tuloluokkaan sijoittuvat suomalaiset asettavat suuremmat yksilön kannustimet tasaisemman tulotason edelle muita tuloluokkia enemmän.
Testiluvun ja p-arvon lisäksi voidaan varianssianalyysistä raportoida myös etan neliö, joka kuvaa sitä, kuinka paljon selitettävän muuttuja vaihtelusta pystytään selittämään selittävän muuttujan avulla. Eta2 on tunnuslukuna verrattavissa regressioanalyysin yhteydessä käytettävään R2-lukuun. Se voi saada arvoja nollan ja yhden väliltä ja suuret arvot kuvastavat selittävän muuttujan parempaa selitysvoimaa. Eta2 ei ole laskettavissa SPSS:n One-Way ANOVA -valikon kautta, mutta yksi tapa laskea se on valita Analyze – Compare Means – Means. Vie selitettävä muuttuja avautuvan ikkunan Dependent List -laatikkoon ja selittävä Layer-laatikkoon, valitse Options ja sieltä 'Anova table and eta' ja paina Continue. Kun painat OK, ohjelma ajaa varianssianalyysin ja Measures of Association -taulukosta näet Eta Squared -arvon, joka on tässä tapauksessa matala: 0,026.
Kaksi- ja useampiulotteiset varianssianalyysit ovat mahdollisia mm. ANOVA-, MANOVA-, GLM- ja UNIANOVA-syntaksikomentojen kautta.