Regressioanalyysi - SPSS-harjoitus 1
Jos olet ensimmäistä kertaa aloittamassa SPSS-harjoitusta, on ennen varsinaisen harjoituksen tekemistä syytä tutustua opiskeluohjeisiin.
Tässä harjoituksessa käytetään Maailmanpankin -tilastoista koottua aineistoa.
Havaintoaineiston hakemisesta SPSS-ohjelmaan on erilliset ohjeet.
Lineaarinen regressioanalyysi

Maailmanpankin väestötilastoaineisto sisältää sekä itsenäisiä valtioita että alueita ja maaryhmiä. Tässä esimerkissä käytetään aineiston kaikkia havaintoyksiköitä, mutta sisällöllisesti mielekkäämpien tulosten aikaansaamiseksi voit kokeilla sisällyttää analyysiin esimerkiksi vain itsenäiset valtiot käyttämällä aineistossa olevaa filtterimuuttujaa (Data - Select Cases - Use Filter Variable).
Tehdään lineaarinen regressioanalyysi aluksi selitettävällä muuttujalla ja yhdellä selittävällä muuttujalla. Selitettävänä muuttujana on suhteellinen kuolleisuus (kuolleiden määrä tuhatta henkilöä kohti), V13 ja selittävänä muuttujana HI-viruksen esiintyvyys väestössä (viruksen kantajien %-osuus 15–49-vuotiaassa väestössä), V28.
SPSS ohjelmistossa lineaarinen regressioanalyysi aloitetaan valikosta Analyze - Regression - Linear...
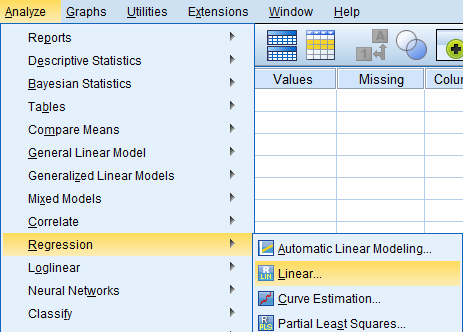
Seuraavassa ikkunassa valitaan selitettävä muuttuja (Dependent) ja selittävät muuttujat (Independent(s)). Method -valinnalla valitaan käytettävä selittävien muuttujien lisäystapa regressiomalliin. Valittavana on suora (Enter) muuttujien lisäys sekä useita askeltavia valintamalleja. Askeltavissa menetelmissä muuttujat lisätään tai poistetaan mallista sen mukaan mikä valinta kasvattaa mallin selitysastetta parhaiten. Automaattisten askeltavien menetelmien käyttöä on kritisoitu, sillä niissä ei pohdita muuttujia sisällöllisesti teorian kautta, vaan katsotaan vain niiden selitysvoimaa, jolloin teorian kannalta olennaisia muuttujia saattaa jäädä mallista pois. Lisätään muuttujat tässä suoraan malliin.
Lisää kuolleisuusmuuttuja Dependent -kenttään ja HI-viruksen esiintyvyys -muuttuja Independent(s) kenttään. Statistics -painiketta klikkaamalla voi valita analyysiin lisätietoja tarkasteltavista muuttujista. Valitse oletuksena valittujen lisäksi Descriptives ja Confidence Intervals (95 %).
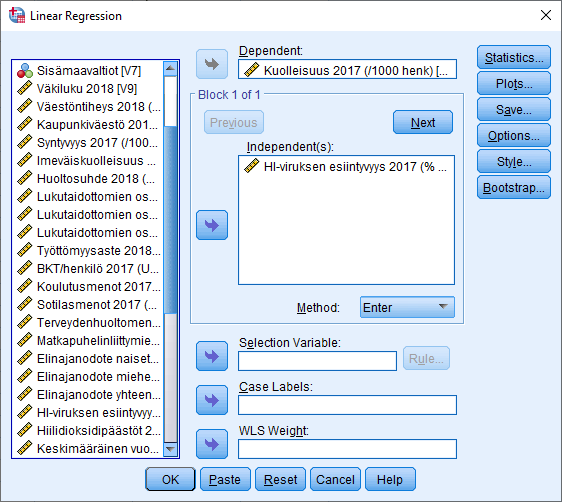
Klikkaa OK ja regressioanalyysin tulokset tulostuvat Output-ikkunaan. Koska valitsimme Descriptives, alkuun tulee tietoa analyysiin sisällytettyjen muuttujien havaintojen määrästä, keskiarvoista, hajonnoista ja korrelaatioista. Regressioanalyysin tulokset tulkitaan Model Summary, ANOVA ja Coefficients -taulukoista.
Model Summary -taulukko kertoo mallin selitysvoimasta. Siinä R Square on mallin selitysosuudesta kertova R2-luku, joka kertoo, että selittävä muuttuja pystyy selittämään n. 3 % selitettävän muuttujan vaihtelusta. Adjusted R Square kertoo korjatun R2-luvun, jota voidaan käyttää vertailtaessa useamman regressiomallin selitysosuuksia. Std. Error of the Estimate puolestaan ilmaisee estimaatin keskivirheen (2,45), joka ilmoittaa regressiomallin residuaalien keskihajonnan.
ANOVA-taulukon kohdalla ollaan yleensä kiinnostuneita F-testin arvosta ja sen tilastollisesta merkitsevyydestä (Sig.), sillä se kertoo, pystyykö selittävillä muuttujilla selittämään selitettävän muuttujan vaihtelua. Tässä tapauksessa p-arvo on pienempi kuin 0,05, joten F-testin tulos on tilastollisesti merkitsevä 95 %:n luottamustasolla. Selittävä muuttujamme kykenee siis selittämään selittävän muuttujan vaihtelua.
Coefficients-taulukosta tulkitaan varsinaiset regressiokertoimet. Sarakkeesta B luetaan standardisoimattomat estimoidut regressiokertoimet. Selittävän muuttujamme kohdalla kerroin on 0,09, mikä tarkoittaa, että kun HIV-sairastuvuus maassa kasvaa yhdellä prosentilla, kasvaa kuolleisuus 0,09 yksikköä. Selittävälle muuttujalle laskettu t-arvon suuruus on 1,99 ja t-testiin perustuva p-arvo (Sig.) on 0,048, joten HIV-tapausten ja kuolleisuuden yhteys on tilastollisesti merkitsevä 95 %:n luottamustasolla. Koska valitsimme Statistics-valikosta Confidence Intervals, taulukossa esitetään myös muuttujien regressiokertoimen arvojen luottamusväli 95 %:n luottamustasolla. Tulosten perusteella voidaan todeta, että HIV-esiintyvyyden regressiokertoimen arvo on valitulla luottamustasolla välillä 0,001 ja 0,184.
Coefficients-taulukon Beta-sarakkeessa ilmoitetaan muuttujan standardoidun regressiokertoimen arvo, jonka avulla voidaan paremmin verrata kahden eriskaalaisen selittävän muuttujan yhteyttä selitettävään muuttujaan. Standardointi muuttaa kertoimen arvon keinotekoiselle asteikolle, minkä vuoksi se ei suoraan kerro sitä, kuinka monta prosenttiyksikköä kuolleisuus muuttuu HI-viruksen esiintyvyyden kasvaessa.
Regressioanalyysin tulosten tulkintaa käsitellään tarkemmin tätä samaa esimerkkiä käyttäen kvantitatiivisten menetelmien käsikirjan regressioanalyysiluvussa.
Useamman muuttujan regressioanalyysi ja dummy-muuttujat
Tässä esimerkissä lineaarinen regressioanalyysi toteutetaan samalla selitettävällä muuttujalla, mutta nyt käytetään useampaa selittävää muuttujaa, joista yksi on järjestysasteikollinen.
Selitettävä muuttuja on jälleen suhteellinen kuolleisuus (V13). Tätä esimerkkiä varten tehdään HI-viruksen esiintyvyyttä tarkastelevasta muuttujasta kaksiluokkainen, jossa matalaan luokkaan (0) kuuluvat maat ja alueet, joissa HIV-esiintyvyys on 0–0,99 % ja korkeaan luokkaan (1) ne, joissa esiintyvyys on 1 % tai enemmän. Uuden muuttujan nimeksi voi antaa esim. HI_virus (ks. tarvittaessa muuttujamuunnosharjoitus 2). Selitettäviksi muuttujiksi valitaan lisäksi suhteellinen syntyvyys (V12), imeväiskuolleisuus (V14), terveydenhuoltomenojen osuus maan tai alueen BKT:stä (V23) sekä maan tai alueen sijoittuminen matalan, alemman keskitason, ylemmän keskitason tai korkean bruttokansantulon ryhmään (V6).
Viimeksi mainittu muuttuja on neljäluokkainen järjestysasteikollinen muuttuja, joten siitä on tehtävä dummy-muuttuja regressioanalyysiä varten (ks. myös regressioanalyysiluvun osio kategoristen muuttujien käyttö regressioanalyysissä). Esimerkkiaineisto sisältää valmiiksi dummy-muuttujat BKTL-muuttujalle, mutta niiden luomista kannattaa myös harjoitella itse.
Dummy-muuttujat voi luoda uudelleenkoodaamalla muuttuja kolmeksi eri muuttujaksi (esim. BKTL alempi keskitaso, BKTL ylempi keskitaso ja BKTL korkea), jotka saavat vain arvot 0 ja 1. Tällöin esimerkiksi korkean BKTL:n muuttujassa ne maat, joiden BKTL on korkea, saavat arvon yksi ja muut maat nolla. Dummy-muuttujia tarvitaan BKTL-muuttujan kohdalla vain kolme, koska yhtä muuttujan luokista käytetään analyysissä vertailuluokkana.
Dummy-muuttujat voi myös luoda SPSS:n valikosta Transform – Create Dummy Variables. Haluttu muuttuja siirretään Create Dummy Variables for -laatikkoon ja Root Names -kenttään kirjoitetaan muuttujalle nimi (esim. tässä V6). OK-painiketta klikkaamalla ohjelma luo dummy-muuttujat jokaiselle alkuperäisen muuttujan luokalle. Regressioanalyysissä yksi näistä jätetään vertailuluokaksi, eli sitä ei oteta mukaan analyysiin.
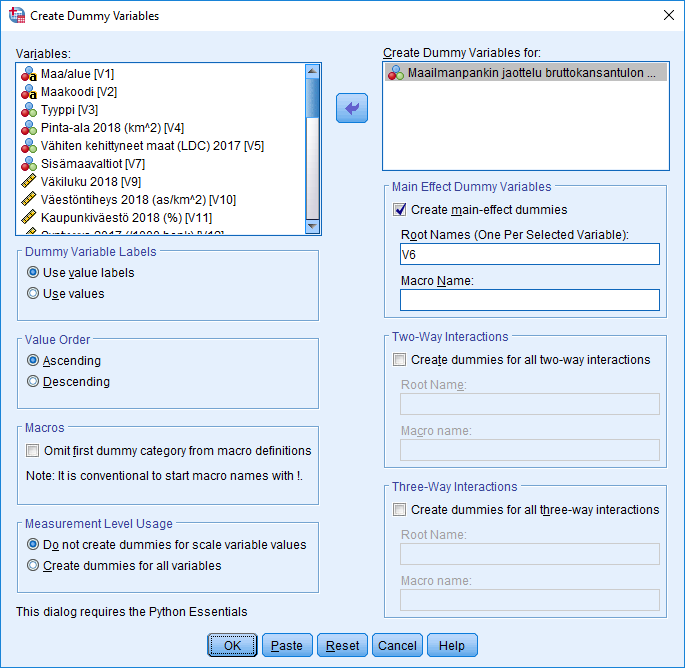
Kun dummy-muuttujat on luotu, ajetaan regressioanalyysi valituilla muuttujilla. Statistics-välilehdeltä voi jälleen valita luottamusvälin (Confidence Intervals) ja kuvailevat tunnusluvut (Descriptives).
Klikkaa OK ja tulokset tulostuvat Output-ikkunaan.
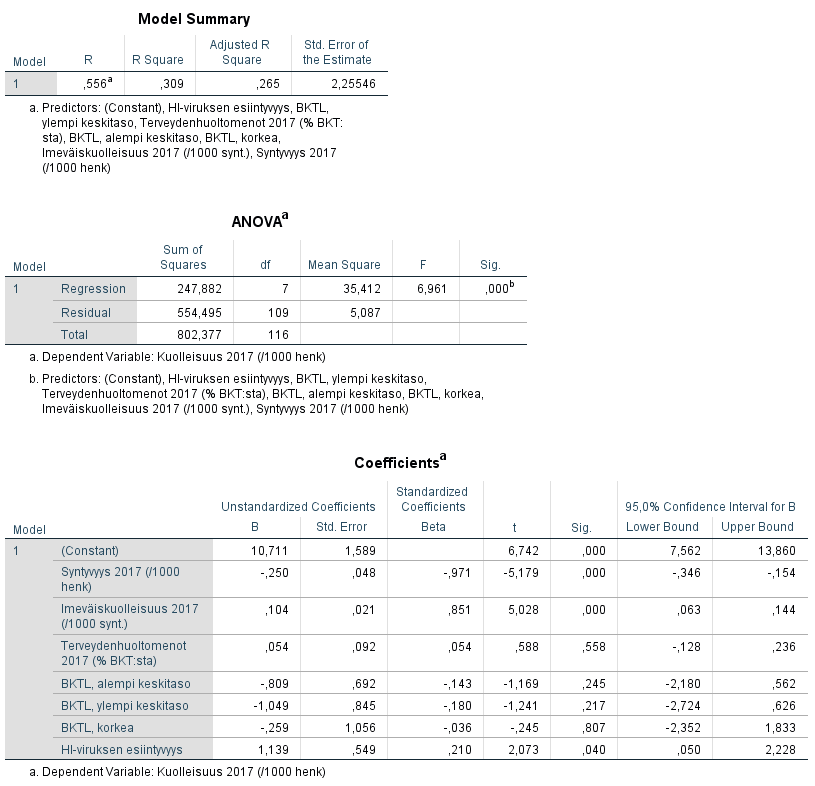
Tulosten perusteella nähdään, että HI-viruksen esiintyvyyden vaikutus säilyy tilastollisesti merkitsevänä (p-arvo = 0,040) muita selittäviä muuttujia lisättäessä. Selittävien muuttujien lisääminen myös paransi mallia selvästi, sillä korjattu R2-luku on nyt 0,27, kun yhden selittävän muuttujan mallissa se oli vain 0,02. Tämän regressioanalyysin tuloksia on tulkittu tarkemmin regressioanalyysiluvun osiossa Usean muuttujan regressioanalyysi.