SPSS-syntaksin käyttö
Annika Valaranta (viittausohje)
On kaksi tapaa käyttää SPSS-ohjelmaa: käyttöliittymän valikkojen tai syntaksiin kirjoitetun ohjelmointikielen avulla. Ohjelmointiteksti kirjoitetaan SPSS:n syntaksi-ikkunaan. Tässä esitellään syntaksin käytön perustoiminnallisuuksia ja komentojen alkeet: miten data haetaan syntaksin avulla käsittelyyn ja miten peruskomennot toimivat.
Ohjelmointikielen käyttämisen keskeisimmät edut verrattuna valikkojen avulla tehtyyn datan käsittelyyn ovat seuraavat:
- Näet aina syntaksista, mitä olet datalle tehnyt. Tämä vähentää virheiden mahdollisuutta.
- Tutkimuksen ja aineiston luotettavuus kasvaa.
- Alkuperäinen data pysyy varmemmin koskemattomana.
- Usein nopeampi tapa käyttää SPSS:ää kuin ikkunoiden klikkailu.
- Käytettävissä on useita tarpeellisia komentoja, joita ei ole valikoissa.
Syntaksi on erityisen hyödyllinen dataan tehtävien muokkausten kuten muuttujamuunnosten ja luokitteluiden käytössä. Syntaksia käyttäessä hyödynnetään usein samanaikaisesti myös käyttöliittymän valikkoja. Valikkoja tarvitaan usein monimutkaisempien analyysien teossa, mutta analyysienkin komennot on hyvä tallentaa syntaksiin Output-ikkunasta. Pohtiessasi esimerkiksi vielä, millä ominaisuuksilla haluat ajaa regressioanalyysin, voit tallentaa eri analyysiversiot (analyysikomennot) syntaksiin ja testata niitä aina uudelleen. Näin säilyy myös tiedoissa, mitä ominaisuuksia kuhunkin analyysiin valitsit. Syntaksitiedosto tulee siis aina tallentaa käytön jälkeen.
Esimerkki syntaksin monipuolisesta hyödyntämisestä voisi olla seuraava: Graduntekijäopiskelijalla on yksi data, mutta kolme syntaksia a, b ja c, koska hän kokeilee samaa regressioanalyysiä eri otoksille. A syntaksiin opiskelija on valinnut kaikki vastaajat, b-syntaksiin kaikki yli 25-vuotiaat ja c-syntaksiin kaikki työssäkäyvät henkilöt.
Syntaksi-ikkunan avaaminen ja perustoiminnallisuudet

Syntaksi-ikkunan avaaminen ja tallentaminen
Avaa haluamasi data tai avaa SPSS-ohjelma. Valitse SPSS:n ylävalikosta File - New - Syntax. Kun syntaksissa on sisältöä, tallenna syntaksi haluamallasi nimellä (File - Save As).
Komennot
Syntaksiin voi kirjoittaa SPSS:n ohjelmointikielen mukaisia komentoja, jotka suorittavat toimintoja dataan. Komentojen tulee päättyä aina pisteeseen. Jos komento on oikein, se on lihavoitu ja sininen. Komennot voi kirjoittaa isoilla tai pienillä kirjaimilla.
Alla esimerkki aktiivisesta komennosta, jossa muuttujan k1 arvo 1 uudelleen koodataan arvoksi 2.
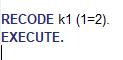
Komennon ajaminen
Komennon kirjoittaminen syntaksiin ei vielä vie toimintoa dataan, vaan se pitää ajaa. Komennon voi ajaa vain, kun datamatriisissa on sisältöä. Ajo tapahtuu maalamalla kursorilla haluttu komento ja painamalla tämän jälkeen ylävalikossa olevaa vihreää nuolta (tai valitsemalla ylävalikosta Run - Selection tai painamalla CTRL+R).
Tämä toiminto suorittaa valitut toiminnot dataan niiden esiintymisjärjestyksessä ylhäältä alaspäin. Komentoja voi ajaa yhden kerrallaan tai monta peräkkäin. Ajossa ei haittaa, vaikka kursorilla maalattu osa se sisältää myös *-merkittyä muuta tekstiä (ks. alla: Kommentit). Komento on ajettu, kun syntaksi-ikkunan alareunassa lukee "IBM SPSS Statistics Processor is ready". Jos alhaalla lukee "Transformations pending", aja EXECUTE. Execute-komento on hyvä laittaa syntaksiin komentojen perään, sillä sen ajamalla komennot toteutuvat dataan. Muista laittaa EXECUTE-komennon loppuun piste. Jos komentoja on monta peräkkäin, EXECUTE-komennon voi laittaa viimeisen komennon perään.
Hienoa syntaksissa on se, että data voidaan ajaa vaikka kuinka monta kertaa, jos esimerkiksi jossain komennossa on virhe. Jos esimerkiksi teet vahingossa luokittelun suoraan ikämuuttujaan luomatta uutta muuttujaa, voit ajaa syntaksin uudelleen alusta datan avaamisesta lähtien.
Huomaa, että et voi ajaa peräkkäin keskenään ristiriitaisia komentoja. Kun valitset ja ajat kaikki syntaksiisi tehdyt komennot, SPSS suorittaa ne kronologisessa järjestyksessä dataan. Huolehdi siis, että komennot ovat halutussa järjestyksessä ajoja tehdessä. SPSS antaa virheilmoituksen, jos esimerkiksi edellisessä komennossa poistettua muuttujaa yritetään muokata seuraavassa komennossa tai jos yritetään antaa selite muuttujalle, jota ei vielä ole datassa.
Kommentit
Syntaksiin voi kirjoittaa myös tavallista tekstiä eli kommentteja. Kommentteja voi laittaa itselleen muistin tueksi: esim. voi selittää mikä luokittelu muuttujalle tehdään ja miksi. Kommentit merkitään *-merkillä ja ne näkyvät syntaksissa harmaalla värillä. *-merkillä voi myös merkata ei-aktiiviseksi komennon tilanteessa, jossa ei haluta komentoa ajettavan.

Output ja syntaksi
Käytettäessä joko valikkoja tai syntaksia datan käsittelyyn, tehdyt toiminnot monistuvat Output-ikkunaan. Output onkin syntaksin käytön oiva liittolainen. Jos et tiedä miten komento kirjoitetaan syntaksiin, tee ensin toiminto valikoilla ja kopioi komento outputista syntaksiin. Huomaa, että ihan kaikkia valikoilla tehtyjä toimintoja ohjelma ei kirjoita Outputiin. Tällaisia toimintoja ovat esim. arvojen selitteiden (value labels) lisääminen.
Virheilmoitukset
SPSS:n antaa virheilmoituksen, jos komentoa ajaessa siinä havaitaan virhe. Virhe tulee syntaksin tekstikentän alapuolelle. Ilmoitus kertoo, millä syntaksin rivillä ongelma on havaittu, mihin komentoon se liittyy ja mikä on ongelman syy. Ilmoitus ongelmasta tulee myös Output-ikkunaan, josta saa usein tarkempaa tietoa ongelmasta. Ongelman sattuessa kannattaa katsoa molemmat paikat.

Datankäsittely syntaksilla – yleisimmät komennot
Datan avaaminen: syntaksi vs. perinteinen klikkaaminen
Käsiteltävän datamatriisin voi avata kahdella tavalla: syntaksin avulla tai klikkaamalla tiedosto "tavallisesti" auki. Syntaksia käyttäessä sinun ei erikseen tarvitse avata varsinaista datatiedostoa ollenkaan, vaan töihin ryhtyessäsi avaat ainoastaan syntaksitiedoston ja ajat datanhakukomennon. Jos aukaiset datan syntaksin avulla, se ei saa olla avattuna muualla koneellasi. Jos et halua hakea datamatriisia syntaksin avulla, syntaksia voi käyttää myös pelkästään komentojen ajossa.
Kun lopetat SPSS:n käytön, ole tarkka datamatriisin tallentamisessa. Jos olet hakenut alkuperäisen datatiedoston ja tehnyt siitä työversion, sinun ei tarvitse tallentaa datamatriisia, koska saat ajettua syntaksista kaikki halutut komennot yhdellä klikkauksella uudelleen.
Datan avaaminen syntaksilla SPSS:n formaateista
SPSS-formaatin data (esim. .sav. tai .por.) haetaan GET FILE -komennolla. Laita lainausmerkkeihin polku, jolla data sijaitsee koneellasi. Jos et tiedä sitä, voit avata datan avaamalla sen perinteisesti klikkaamalla ja kopioimalla GET FILE -komennon Outputista. GET FILE -komennon jälkeen ei tarvitse käyttää EXECUTE-komentoa.
*Haetaan alkuperäinen data.
GET FILE = 'C:\Gradu\analyysit\koyhyysdata.sav'.
On suositeltavaa, että datasta tallennetaan työversio, jotta muokkaukset eivät tallennu vahingossakaan alkuperäiseen dataan.
*Työversion tallentaminen.
SAVE OUTFILE = 'C:\Gradu\analyysit\koyhyysdata_tyoversio.sav'.
GET FILE = 'C:\Gradu\analyysit\koyhyysdata_tyoversio.sav'.
Datan avaaminen Excelistä tai muista tiedostotyypeistä
Excel-tiedostojen ja muiden formaattien kohdalla helpoin tapa avata datat SPSS:ään on tehdä sen ensin valikkojen kautta File - Open - Data jne. ja kopioida Output-ikkunaan tulostunut avaussyntaksi syntaksiin. Esim. komento excel-tiedoston avaamiseksi näyttää tältä:
GET DATA /TYPE=XLSX
/FILE= 'C:\Gradu\analyysit\koyhyysdata.xlsx'
/SHEET=name 'Kaikki vastaukset'
/CELLRANGE=range 'A1:CL1641'
/READNAMES=on
/DATATYPEMIN PERCENTAGE=100.0
/ASSUMEDSTRWIDTH=32767.
EXECUTE.
SHEET määrittää Excelin välilehden nimen.
CELLRANGE määrittää luettavan alueen matriisissa.
READNAMES kertoo, että muuttujien nimet luetaan Excelin matriisin 1. riviltä.
DATATYPEMIN PERCENTAGE Tähän kannattaa muuttaa prosenttiluvuksi 100.0, jotta myös sellaisille muuttujille, joissa on vain muutama vastaus, saadaan määritellyksi oikea muuttujatyyppi (numeerinen tai teksti).
ASSUMEDSTRWIDTH määrittää oletusarvoisesti string-muuttujien pituudeksi 32767 merkkiä.
Muuttujien uudelleennimeäminen
Muuttujien nimeäminen uudelleen syntaksin avulla on yksinkertaista. Kirjoita komento RENAME VARIABLES ja sen jälkeen sulkuihin vanhan muuttujan nimi = uuden muuttujan nimi. Voit nimetä useita muuttujia uudelleen kerralla.
RENAME VARIABLES (k1=k1avo) (k2=k2muu).
EXECUTE.
Muuttujien selitteen antaminen muuttujalle
Esimerkissä annetaan muuttujalle k1 muuttujan selite, joka on usein kyselylomakkeen kysymys. Selitteen sisään laitettu hakasulku ja muuttujan nimi helpottavat käsittelyä SPSS:ssä, esim. jakaumia ajaessa, koska selitteessä näkyy myös muuttujan numero.
VARIABLE LABELS k1 "[k1] Muuttujan q1 kysymysteksti tähän".
EXECUTE.
Muuttujien uudelleen luokittelu RECODE-komennolla
Esimerkissä luokitellaan jatkuva ikämuuttuja kymmenen vuoden välein ja niin, että ääriarvot luokitellaan yhteen lowest ja highest -määritelmien avulla (nk. TOP- ja BOTTOM-koodaus). Uusi muuttuja nimetään muuttujaksi k1_1. Käytä määritelmää 'thru' (through) lukujen väliä ilmaistessa, älä viivaa!
RECODE k1 (LOWEST thru 19=1) (20 thru 29=2) (30 thru 39=3) (40 thru HIGHEST=5) INTO k1_1.
EXECUTE.
Valikoiden kautta komento on nimellä: Recode into Different Variables. Jos haluat tehdä muutoksen samaan muuttujaan, jätä INTO-komento pois. Uudelleen luokittelun jälkeen uuden muuttujan k1_1 arvoille voi antaa selitteet VALUE LABELS -komennolla.
Arvojen selitteiden nimeäminen
Arvojen selitteet nimetään VALUE LABELS -komennolla esimerkin kaltaisesti. Esimerkissä annetaan ikäluokkamuuttujalle selitteet.
VALUE LABELS k1_1
1 "-19"
2 "20-29"
3 "30-39"
4 "40-".
EXECUTE.
Muuttujan muotoileminen ehdollisesti IF-komennolla
IF-komentoa voi käyttää arvojen luokitteluun jonkin ehdon kautta. Esimerkiksi, jos haluaa muuttaa vain miespuolisten (k1=1) vastaajien vastaukset ryhmään 2 muuttujassa k2, se tehdään seuraavalla tavalla. IF-komennolla ei voi muuttaa arvoja puuttuviksi sysmis-arvoiksi.
IF (k1=1) k2=2.
EXECUTE.
IF-komentoa voi käyttää myös string-muotoisissa eli tekstimuodossa olevissa muuttujissa. Korvattavan tekstin on oltava lainausmerkeissä.
IF (k1="koira") k2="nisäkäs".
EXECUTE.
Jos halutaan muuttaa arvo ehdollisesti puuttuvaksi arvoksi, se voidaan tehdä DO IF-komennolla. Tässä kuvitteellisessa esimerkissä muutetaan miespuoliset vastaajat (k1=1) puuttuviksi sysmis-arvoiksi muuttujassa k2.
DO IF k1=1.
RECODE k2 (else=sysmis).
END IF.
EXECUTE.
Muuttujien merkitseminen puuttuvaksi tiedoksi
Luokitellaan syntymävuosimuuttujan k2 virheelliset arvot 100 ja 12200 puuttuviksi tiedoiksi (sysmis).
RECODE k2 (100,12200=SYSMIS).
Yksilöllisen tunnistemuuttujan luominen
Komento luo 1:stä eteenpäin juoksevan id-muuttujan.
COMPUTE id = $CASENUM.
Avovastausten anonymisointi
Jos avovastauksia haluaa anonymisoida tai koodata luokiksi, sen voi tehdä RECODE-komennolla käyttämällä tekstien ympärillä puolilainausmerkkejä tai lainausmerkkejä. Jos teksti sisältää jo valmiiksi puolilainaus- tai lainausmerkkejä, käytä tekstin ympärillä eri merkkejä, jotta komento ei katkea väärässä kohdassa. Matriisista haettavan tekstin on oltava täsmälleen siinä muodossa kuin matriisissa, jotta komento toimii.
RECODE k1 ("Kati Kattinen opetti minua alakoulussa"="[Nainen] opetti minua alakoulussa").
EXECUTE.
Sama voidaan tehdä myös IF-toimintoa käyttäen. Tällöin tekstin ei tule olla täydellisenä lainausmerkeissä vaan riittää, että siinä on uniikki tunniste esim. edellisen lauseen nimi Kati Kattinen, jos sitä ei ole muissa k1-muuttujan avovastauksissa.
IF (char.index (k1, "Kati Kattinen")NE 0) k1 = "[Nainen] opetti minua alakoulussa ".
EXECUTE.
Avovastausten luokittelu luokiksi ja muuttaminen numeerisiksi
Jos vastauksen haluaa luokitella kategoriseksi muuttujaksi sen voi tehdä esimerkiksi RECODE-komennolla. Tässä luodaan uusi muuttuja k1avo.
Tekstimuuttuja (string) pitää ensin luoda. Suluissa oleva komento määrittelee tekstimuuttujan pituuden 100 merkkiin.
STRING k1avo (A100).
EXECUTE.
RECODE k1 ("Ala-asteella minusta oli kurjaa nähdä, kun kavereitani kiusattiin"="1") INTO k1avo.
EXECUTE.
Uusi muuttuja k1avo voidaan muuttaa numeeriseksi ALTER TYPE -komennolla. Suluissa oleva luku määrittelee mahdollisten numeroiden ja desimaalien määrät. Tässä esimerkissä desimaalipilkkua edeltävä arvo saa olla enintään viisinumeroinen ja desimaalien määrä enintään 2 (esim. 52038,44).
ALTER TYPE k1avo (F5.2).
EXECUTE.
Komennon jälkeen voit antaa muuttujalle arvojen selitteet VALUE LABELS -komennolla.
Tekstimuotoisen muuttujan muuttaminen numeeriseksi
Joskus muuttujat tulevat kyselytyökaluista tekstimuotoisina, vaikka haluaisimme niiden olevan numeerisia. Vain numeroita sisältävät string-muuttujat saadaan muutettua numeerisiksi ALTER TYPE -komennolla. Tässä esimerkissä F5.1-tekstillä määritellään arvolle mahdollisten numeroiden ja desimaalien määrä, eli desimaalipilkun vasemmalla puolella saa olla 5-numeroinen luku ja oikealla puolella yksi luku.
ALTER TYPE k1 (F5.1).
EXECUTE.
Komennon jälkeen voit antaa muuttujalle arvojen selitteet VALUE LABELS -komennolla.
Jos avovastaus sisältää kirjoitettua tekstiä kannattaa käyttää AUTORECODE-komentoa. Alla olevassa esimerkissä string-muuttuja k1 muutetaan uudeksi muuttujaksi k1a.
AUTORECODE VARIABLES=k1 /INTO k1a.
EXECUTE.
Komento muuttaa string-muuttujan arvot juoksevassa järjestyksessä numerosta yksi eteenpäin. Voit järjestellä luokkia tämän jälkeen RECODE-komennolla haluamallasi tavalla.
Havaintojen poistaminen
Joskus datassa halutaan käsitellä vain osaa vastaajista. Jos esimerkiksi data sisältää suomalaisia (k=1) ja ruotsalaisia (k1=2), mutta halutaan tutkia vain suomalaisia, havainnot voidaan pudottaa SELECT IF-komennolla.
SELECT IF k1=1.
EXECUTE.
tai
SELECT IF (k1 eq 1).
EXECUTE.
Myös yksittäisiä havaintoja voi pudottaa datasta, esim. duplikaatteja, paljon puuttuvia tietoja sisältävät vastaukset yms. Alla poistetaan vastaajat, joiden id-numerot ovat 1237 ja 1243. Ne=not equal. Toisin sanoen valitaan ne havainnot dataan, joiden havaintotunnus eli ID ei ole yhtä kuin 1237 ja 1243.
SELECT IF (ID ne 1237 and ID ne 1243).
Muuttujien pudottaminen
Muuttujia voi pudottaa datasta SAVE OUTFILE -komennon yhteydessä joko valitsemalla KEEP-komennolla kaikki valittavat muuttujat tai pudottamalla halutut DROP-komennolla. Saat tulostettua syntaksiin kaikki muuttujat valitsemalla Utilities - Variables - valitse kaikki muuttujat - Paste. Näin sinun ei tarvitse kirjoittaa jokaista muuttujaa käsin syntaksiin.
KEEP-komento:
SAVE OUTFILE = 'C:\Gradu\analyysit\koyhyysdata_ruotsalaiset.sav'/KEEP=k1 k2 k3 k4 k5 k6.
GET FILE = 'C:\Gradu\analyysit\koyhyysdata_ruotsalaiset.sav'.
DROP-komento:
SAVE OUTFILE = 'C:\Gradu\analyysit\koyhyysdata_ruotsalaiset.sav'/DROP=k7 k8.
GET FILE = 'C:\Gradu\analyysit\koyhyysdata_ruotsalaiset.sav'.
Merkistöasetukset
Jos datassa eivät näy skandimerkit (åäö), vaihda merkistö paikalliseen kieleen. Tämä tulee tehdä, kun auki on tyhjä datamatriisi.
NEW FILE.
SET UNICODE OFF.
SET LOCALE = 'fi_FI.windows-1252'.
Esimerkki syntaksista
Valmis syntaksi voi näyttää vaikkapa tältä:
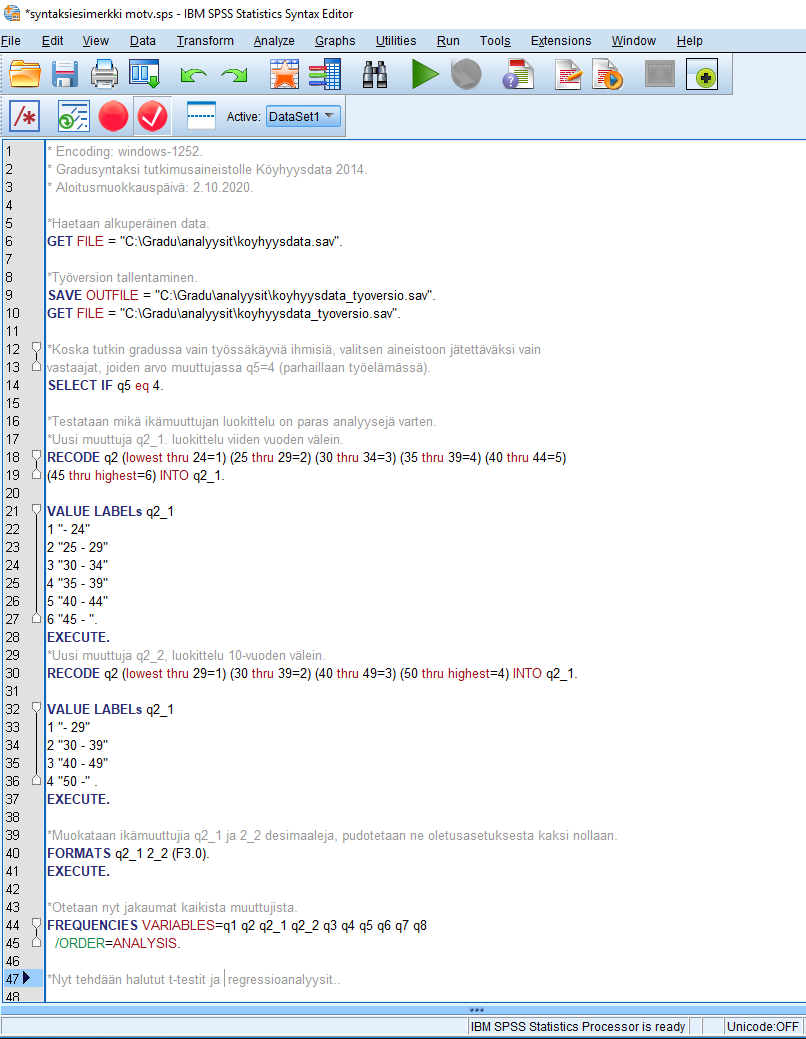
Kommentoimalla tehtyjä muutoksia on helpompi myöhemmin muistaa, mitä mikin komento tekee.