Hypoteesien testaus - SPSS-harjoitus 1
Jos olet ensimmäistä kertaa aloittamassa SPSS-harjoitusta, on ennen varsinaisen harjoituksen tekemistä syytä tutustua opiskeluohjeisiin.
Voit harjoitella riippumattomien otosten t-testin laskemista oheisen videon avulla, jossa käytetään European Social Survey 2012 -kyselyn Suomen aineistoa.
Alla olevia ohjeita seuraamalla voit harjoitella yhden otoksen, kahden riippumattoman otoksen ja kahden riippuvan otoksen t-testin laskemista SPSS:llä. Kahdessa ensimmäisessä käytetään havaintoaineistona vuoden 2014 European Social Survey -tutkimuksen Suomen aineistoa. Koko aineisto on vapaasti ladattavissa Ailasta ilman rekisteröitymistä.
Havaintoaineiston hakemisesta SPSS-ohjelmaan on erilliset ohjeet.
Hypoteesien testaus - Parametriset testit

Tässä SPSS-harjoituksessa käydään läpi muutamia yleisimpiä hypoteesitestejä aineiston analysoinnissa. Jos testi vaatii, että perusjoukko noudattaa jotain tiettyä todennäköisyysjakaumaa (erityisesti normaalijakaumaa), sanotaan testiä parametriseksi testiksi. Jos jakaumaoletusta ei ole, testiä kutsutaan ei-parametriseksi testiksi (nonparametric). Parametriset testit ovat tehokkaampia ja mikäli oletukset ovat voimassa, niitä kannattaa käyttää. Ei-parametrisia testejä käsitellään harjoituksessa kaksi.
T-testi
T-testiä voidaan käyttää yhden otoksen keskiarvon testaamiseen, kahden riippumattoman otoksen tai kahden riippuvan otoksen keskiarvojen yhtäsuuruuden testaamiseen. Riippuvilla otoksilla käytännössä tarkoitetaan mittaustilannetta, jossa samoja koehenkilöitä mitataan jonkin ajan kuluttua uudestaan. Selitettävän muuttujan tulee olla välimatka- tai suhdeasteikollinen.
Normaalijakautuneisuuden testaaminen
Parametrisenä testinä t-testiä voidaan soveltaa ainoastaan, jos otos on poimittu perusjoukosta, joka on normaalijakautunut. Ennen testin käyttöä tulisi testata perusjoukon normaalisuus. Edellytys normaalisuudesta voi usein näyttää muodostuvan testin esteeksi, koska kaikki ominaisuudet eivät jakaudu normaalisti perusjoukossa. T-testit eivät kuitenkaan ole erityisen herkkiä normaalista poikkeaville jakaumille, kunhan otoskoot ovat riittävän suuria (keskeiseen raja-arvolauseeseen perustuen yli 30 on jo riittävä havaintojen määrä).
Erityisesti silloin, kun otos on kovin pieni, on suositeltavaa käyttää sekä normaalisuustestejä että jakauman graafista tarkastelua normaalisuuden selvittämiseksi. Testit ja graafisen tarkastelun saa ajettua SPSS:llä helposti samalla komennolla: Analyze – Descriptive Statistics – Explore. Tarkasteltava muuttuja siirretään Dependent List -laatikkoon. Plots-painikkeella avautuvasta ikkunasta valitaan 'Histogram' ja 'Normality plots with tests'. Continue ja OK tulostaa Output-ikkunaan muuttujasta kuvailevia tietoja, normaalisuustestit, histogrammin, kvantiilikuviot sekä mahdollisesti muita kuvioita, jos nämä olivat valittuina.
Jakauman tarkastelussa ollaan lähinnä kiinnostuneita normaalisuuden testeistä, histogrammista ja kvantiilikuviosta. Explore-toiminnolla suoritettavat normaalisuustestit ovat Kolmogorovin–Smirnovin sekä Shapiron–Wilkin testi. Normaalisuuden testaamiseen on olemassa monia muitakin testejä, mutta nämä kaksi ovat usein käytettyjen joukossa. Testeistä, niiden toimintaperiaatteista ja rajoitteista voit lukea lisää alan kirjallisuudesta.
Kolmogorovin–Smirnovin (K–S) testiä käytetään yleensä, kun havaintoja on enemmän (≥ 50) ja Shapiron–Wilkin (S–W) testiä, kun niitä on vähemmän, mutta S–W -testikin sopii vielä parin tuhannen havaintomäärille. Tässä mainittua K–S -normaalisuustestiä ei kannata sekoittaa lähes samannimiseen (ja samankaltaiseen) Kolmogorovin–Smirnovin Z-testiin, jota käsitellään harjoituksessa 2.
Molempien testien tuloksia on helppo tarkastella rinnakkain SPSS:n tulostamassa taulukossa. Kummassakin testissä nollahypoteesinä on, että muuttuja on normaalisti jakautunut. Tällöin pienet p-arvot (valitusta riskitasosta riippuen esim. < 0,05) tukevat vaihtoehtoista hypoteesiä, eli sitä, että jakauma ei ole normaalisti jakautunut. Huomaa, että suurella otoskoolla melko vaatimattomatkin muuttujan vaihtelut voivat vaikuttaa siihen, että nollahypoteesi hylätään, vaikka havainnot tosiasiassa jakautuisivatkin normaalisti.
Sekä histogrammia että kvantiilikuviota (Q-Q plot) voidaan käyttää jakauman normaalisuuden arvioimiseen, mutta jälkimmäisen tulkinta on usein helpompaa. Histogrammin tulkintaa on käsitelty frekvenssijakauman harjoituksissa 1, joten tässä ei käydä sitä läpi. Kvantiilikuvion tulkinta on varsin yksinkertaista: mitä lähempänä suoraa pisteet ovat, sitä lähempänä normaalijakaumaa jakauma on. Täydellisesti normaalijakaumaa noudattavalla jakaumalla pisteet asettuvat viivalle täsmälleen.
Jakauman tarkastelu vaatii tulkintaa, minkä vuoksi on hyvä huomioida testien ja graafisen tarkastelun tulokset ja rajoitukset sekä raportoida päätelmät ja tehdyt valinnat asianmukaisesti.
Yhden otoksen t-testi
Yhden otoksen t-testissä nollahypoteesina (H0) on, että tarkasteltavan muuttujan keskiarvo on yhtä kuin X, missä X on tutkijan määrittelemä testattava arvo. Kaksisuuntaisessa testissä vastahypoteesi (H1) on tällöin kaksisuuntaisessa testissä: muuttujan keskiarvo on erisuuri kuin X.
Testataan SPSS-ohjelmistolla European Social Survey 2014 -aineiston muuttujan E11 'Pituus' avulla, onko tutkimuspopulaation pituuden keskiarvo yhtä kuin 170 cm. Analyysi aloitetaan määrittämällä keskiarvoa vääristävät vastausvaihtoehdot 998 'Kieltäytyy' ja 999 'EOS' puuttuvaksi tiedoksi. (Ks. muuttujamuunnokset ja puuttuvan tiedon käsittely.)
Valitaan tämän jälkeen valikosta Analyze - Compare Means - One-Sample T Test....
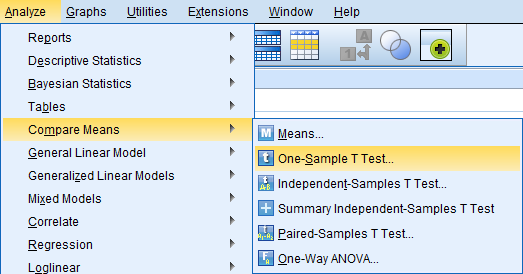
Avautuvasta ikkunasta valitaan tarkasteltava muuttuja E11 ja siirretään se keskellä olevaa nuolta käyttämällä Test Variable(s): -laatikkoon. Test Value: -laatikkoon kirjoitetaan testattava keskiarvo 170 ja painetaan OK-näppäintä. Options... -näppäintä painamalla voi määritellä laskettavan luottamusvälin (oletus 95%) sekä sen, miten puuttuvaa tietoa käsitellään. Tässä tapauksessa käytämme oletusasetuksia.
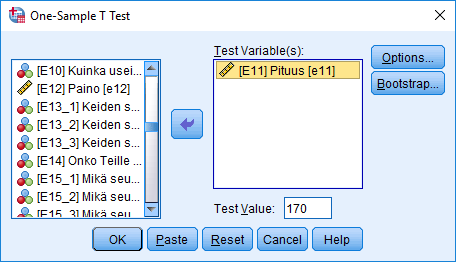
Tulostaulukot tulostuvat tulosikkunaan. Otoksen keskiarvo on 171,00, t-testisuureen arvo on 4,767 vapausastein 2075 ja p-arvo on 0,000, joten nollahypoteesi hylätään yleisimmillä riskitasoilla (1%, 5%). Tutkimuspopulaation pituuden keskiarvon ero testattavaan arvoon 170 on tilastollisesti erittäin merkitsevä.
Tulos ei ole yllättävä, sillä vuonna 2014 suomalaisen väestön keskipituus oli itse asiassa sama kuin tarkastelemamme otoksen keskiarvo, 171 cm (THL: Suomalaisen aikuisväestön terveyskäyttäytyminen ja terveys, kevät 2014). Tässä esimerkissä ei huomioitu sitä, että pituutta tutkiessa voisi olla järkevää tarkastella pituuksia sukupuolittain ja tehdä erilliset hypoteesien testaukset naisten ja miesten keskipituuksille (ks. aineiston jakaminen ryhmiin Split file -toiminnolla).
Kahden riippumattoman otoksen t-testi
Kahden riippumattoman otoksen t-testissä nollahypoteesina (H0) on, että tarkasteltavan muuttujan keskiarvo on yhtäsuuri kummassakin riippumattomassa tarkasteluryhmässä. Vastahypoteesi (H1) on tällöin kaksisuuntaisessa testissä: muuttujan keskiarvot ryhmissä ovat erisuuret.
Käytetään esimerkkinä samaa muuttujaa kuin yhden otoksen t-testissäkin eli European Social Survey 2014 -aineiston muuttujaa E11 'Pituus', mutta nyt verrataan sukupuoliryhmien eroa.
Nollahypoteesi on tällöin: Sekä naisten että miesten pituuksien keskiarvot ovat yhtä suuret.
Vastahypoteesi on: Miesten ja naisten pituuksien keskiarvot ovat erisuuret.
Käytetään jälleen muuttujaa E11, jossa keskiarvoa vääristävät vastausvaihtoehdot 998 'Kieltäytyy' ja 999 'EOS' on merkitty puuttuvaksi tiedoksi. Valitaan tämän jälkeen valikosta Analyze - Compare Means - Independent-Samples T Test.... Avautuneessa ikkunassa valitaan muuttuja E11 Test Variable(s): -laatikkoon ja sukupuolimuuttuja (F2_1) Grouping Variable: -laatikkoon. Define Groups... -näppäimellä määritellään sukupuolimuuttujan vastausvaihtoehdot (1 ja 2) ryhmät määrääviksi arvoiksi. Jos selittävä muuttujamme olisi jatkuva, voisimme käyttää Cut point -asetusta määrittämään arvon, jonka molemmin puolin havainnot jaetaan kahteen ryhmään. Options-näppäintä painamalla voi määritellä laskettavan luottamusvälin (oletus 95%) sekä sen, kuinka puuttuvaa tietoa käsitellään. Käytämme jälleen oletusasetuksia.
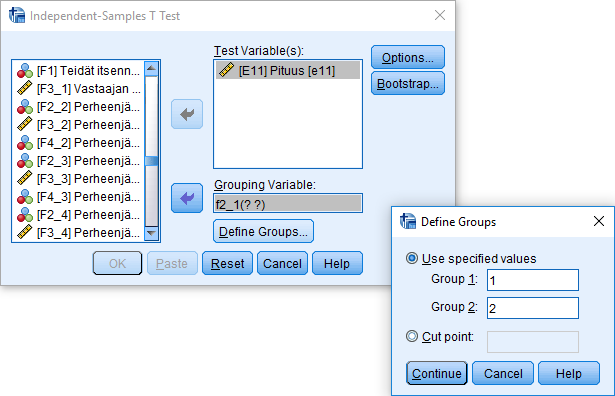
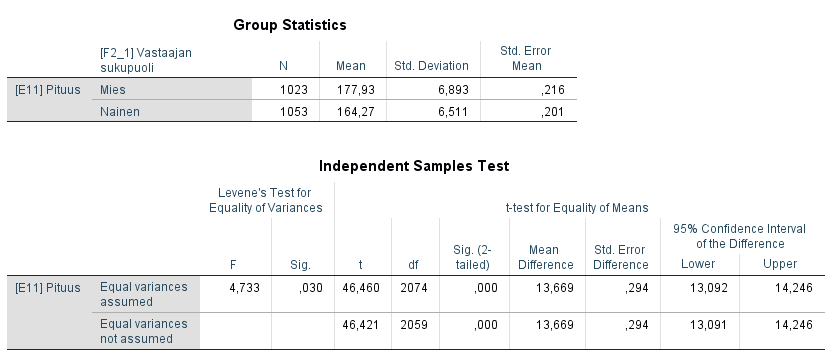
Painamalla OK-näppäintä tulostaulukot ilmestyvät tulosikkunaan. Ylemmästä taulukosta huomaamme, että miesten pituuden keskiarvo otoksessa on 177,93 ja naisten 164,27.
Alemmassa tulostaulukossa on kahden testin tulokset. Riippumattomien otosten t-testissä oletetaan paitsi, että mitta-asteikko on välimatka- tai suhdeasteikollinen ja muuttuja on normaalisti jakautunut tarkasteltavilla ryhmillä, myös että varianssit ovat ryhmissä likimain yhtä suuret. SPSS laskee siksi Levenen testin varianssin yhtäsuuruudelle, jonka perusteella oletetaan varianssit joko yhtä suuriksi tai erisuuriksi. Levenen testissä nollahypoteesi on, että varianssit ovat (likimain) yhtä suuret, jolloin suurempi p-arvo (valitusta riskitasosta riippuen esim. > 0,05) viittaa yhtä suuriin variansseihin ja pienempi taas erisuuriin.
Levenen testin perusteella nollahypoteesi yhtä suurista variansseista ei jää voimaan (p = 0,03), joten tarkastelemme riviä "Equal variances not assumed" alemmasta tulostaulukosta. T-testisuureen arvoksi saadaan 46,421 vapausastein 2058,844 ja p-arvo ≤ 0,001, joten nollahypoteesi hylätään yleisimmillä riskitasoilla. Tutkimuspopulaatiossa miesten ja naisten pituuksien keskiarvojen ero on siis tilastollisesti merkitsevä.
Kahden riippuvan otoksen t-testi
Riippuvilla otoksilla käytännössä tarkoitetaan mittaustilannetta, jossa samoja koehenkilöitä mitataan jonkin ajan kuluttua (jonkin "käsittelyn" jälkeen) uudestaan. Kuten muissa t-testeissä, myös riippuvien otosten t-testissä ovat voimassa oletukset normaalijakautuneisuudesta ja välimatka- tai suhdeasteikollisesta mitta-asteikosta.
Kahden riippuvan otoksen t-testissä nollahypoteesina (H0) on, että tarkasteltavien muuttujien (mittaustulosten) keskiarvot ovat yhtäsuuret. Vastahypoteesi (H1) on tällöin kaksisuuntaisessa testissä: muuttujien keskiarvot ovat erisuuret.
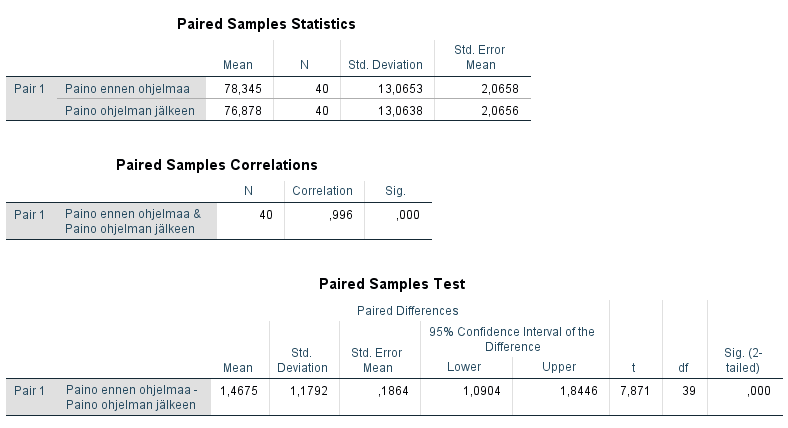
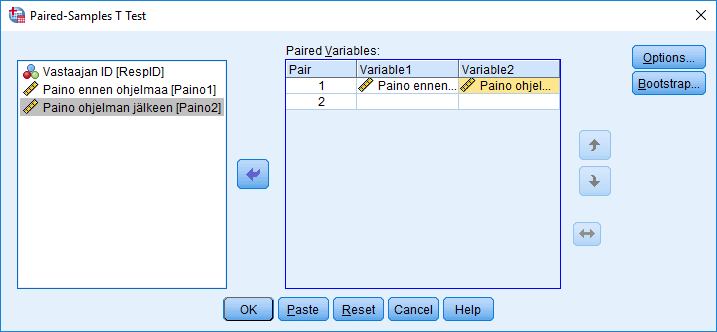
Käytämme esimerkkinä kuvitteellista aineistoa, jossa halutaan tarkastella uuden harjoitus- ja ravinto-ohjelman vaikutusta 40 satunnaisesti valitun koehenkilön painoon testijakson jälkeen. Muuttujina tarkastelussa ovat koehenkilön paino ennen ohjelman noudattamista ja sen jälkeen.
Valitaan valikosta Analyze - Compare Means - Paired-Samples T Test.... Avautuneessa ikkunassa valitaan tarkasteltavat muuttujat Paired Variables -laatikkoon. Options-näppäintä painamalla voi jälleen määritellä laskettavan luottamusvälin (oletus 95%) sekä sen, kuinka puuttuvaa tietoa käsitellään.
Painamalla OK-näppäintä tulostaulukot ilmestyvät tulosikkunaan. Ylimmästä taulukosta huomaamme, että lähtöpainon keskiarvo 78,35 on korkeampi kuin painon keskiarvo ohjelman jälkeen (76,88). Keskihajonta otoksilla on samaa suuruusluokkaa. Keskimmäisessä taulukossa on laskettu korrelaatiokerroin 0,996, joka tilastollisesti poikkeaa nollasta erittäin merkitsevästi (p = 0,000). Korrelaatiokerroin saa usein korkean arvon, kun vertaillaan muuttujien arvoja pareittain.
Alimmassa taulukossa näemme tuloksen erotukselle paino ennen ohjelmaa - paino ohjelman jälkeen. T-testisuureen arvo on 7,871 vapausastein 39. Erotuksen keskiarvo on positiivinen (1,468) ja t-testin p-arvo < 0,001, joten testijaksolla oli tilastollisesti erittäin merkitsevästi vaikutusta osallistujan painon putoamiseen.