Hypoteesien testaus - SPSS-harjoitus 2
Jos olet ensimmäistä kertaa aloittamassa SPSS-harjoitusta, on ennen varsinaisen harjoituksen tekemistä syytä tutustua opiskeluohjeisiin.
Tässä harjoituksessa käytetään havaintoaineistona vuoden 2019 ISSP-tutkimuksen Suomen osa-aineistoa, osaISSP.
Havaintoaineiston hakemisesta SPSS-ohjelmaan on erilliset ohjeet.
Hypoteesien testaus - Ei-parametriset testit

Tässä SPSS-harjoituksessa käydään läpi muutamia yleisimpiä hypoteesitestejä aineiston analysoinnissa. Jos testi vaatii, että perusjoukko noudattaa jotain tiettyä todennäköisyysjakaumaa (erityisesti normaalijakaumaa), sanotaan testiä parametriseksi testiksi. Jos jakaumaoletusta ei ole, testiä kutsutaan ei-parametriseksi testiksi (nonparametric). Parametriset testit ovat tehokkaampia ja mikäli oletukset ovat voimassa, niitä kannattaa käyttää. Parametrisia testejä käsitellään harjoituksessa yksi.
Khii-toiseen yhteensopivuustesti
Khii-toiseen -yhteensopivuustesti (
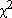 \( x_2 \)
tai
chi-square) vertaa muuttujan jakaumaa hypoteesin mukaisiin frekvensseihin, oletushypoteesijakaumana SPSS käyttää tasajakaumaa. Nollahypoteesina on, että tarkasteltava jakauma noudattaa hypoteesijakaumaa. (Ks. lisäksi
khii-toiseen testistä ristiintaulukoinnissa. Testi on sama, mutta käyttötarkoitus tässä hieman erilainen.)
\( x_2 \)
tai
chi-square) vertaa muuttujan jakaumaa hypoteesin mukaisiin frekvensseihin, oletushypoteesijakaumana SPSS käyttää tasajakaumaa. Nollahypoteesina on, että tarkasteltava jakauma noudattaa hypoteesijakaumaa. (Ks. lisäksi
khii-toiseen testistä ristiintaulukoinnissa. Testi on sama, mutta käyttötarkoitus tässä hieman erilainen.)
Khii toiseen -yhteensopivuustestiä käytettäessä muuttujien mitta-asteikon tulee olla luokittelu- tai järjestysasteikollinen. Kuten ristiintaulukoinnin yhteydessä, luokissa on oltava riittävästi havaintoja, jotta testi toimii oikein (vähintään 5 havaintoa yhdessä solussa).
Tutkitaan ISSP 2019 -aineiston muuttujan k51 'Minkä puolueen ehdokasta äänestit eduskuntavaaleissa 2019?' avulla, noudattaako aineistosta laskettava puolueiden kannatusjakauma otoksen 18–74 -vuotiaassa väestössä samaa kannatusjakaumaa kuin kaikkien äänestysikäisten kohdalla eduskuntavaaleissa 2019 (Tilastokeskus, 2019), joissa puolueiden kannatus oli seuraava:
| puolue | kannatus (%) |
| SDP | 17,7 |
| PS | 17,5 |
| KOK | 17,0 |
| KESK | 13,8 |
| VIHR | 11,5 |
| VAS | 8,2 |
| RKP | 4,5 |
| KD | 3,9 |
| MUUT | 6,0 |
Muodostetaan muuttujan k51 avulla uusi muuttuja puka, johon sisällytetään yllä mainitut puolueet ja luokitellaan vastausvaihtoehdot 10 'En halua sanoa' ja 11 'En osaa sanoa' puuttuvaksi tiedoksi. (Ks. tarvittaessa muuttujamuunnoksia käsittelevät harjoitukset). Vaihtoehtoisesti voit käyttää suoraan muuttujaa k51, kunhan merkitset arvot 10 ja 11 puuttuvaksi tiedoksi. Huomaa, että tämä harjoitus tehdään poikkeuksellisesti painottamattomalla aineistolla (ks. aineiston painottaminen).
Aloita khii-toiseen yhteensopivuustesti valikosta Analyze - Nonparametric Tests - Legacy Dialogs - Chi-Square.... Siirrä puka-muuttuja Test Variable List: -laatikkoon. Expected Range -kohdassa voidaan Use specified range -valinnalla määrätä tutkittavalle muuttujalle arvoalue, jonka arvoilla khii-toiseen -testi suoritetaan. Valitse nyt Get from data, joka ottaa mukaan kaikki arvot.
Expected Values -kohdassa määritellään testattava frekvenssijakauma, johon khii-toiseen -testi vertaa tutkittavan muuttujan jakaumaa. Valitse Values: -kohta ja kirjoita hypoteesin mukaisen jakauman odotetut frekvenssit (All categories equal -valinnalla vertailu tehtäisiin tasajakaumaan).
Odotetut frekvenssit annetaan siinä järjestyksessä, missä tutkittavan muuttujan vastausvaihtoehdot ovat. Koska tutkittavassa puka-muuttujassa on 684 validia vastausta, syötettäviksi arvoiksi saadaan yllä olevan eduskuntavaalien 2019 kannatusjakauman perusteella:
0,175 * 684 = 120
ja niin edelleen: 116, 94, 79, 56, 31, 27 ja 40.
Syötettävien arvojen summan tulee olla sama kuin tutkittavan muuttujan validien arvojen määrä (tässä 684) eli jonkun luvun voi joutua pyöristämään 'väärään' suuntaan (tässä pyöristys 'väärään' suuntaan on tehty ryhmään 9 'MUUT'). Kunkin arvon jälkeen napsauta Add-painiketta. Suorita testi painamalla OK.
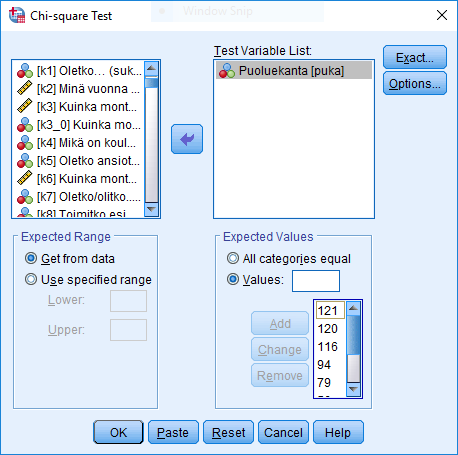
Tulosikkunaan tulostuu taulukko, josta löytyvät ryhmittäiset havaitut ja hypoteesin mukaiset frekvenssit sekä residuaalit (residuaali = havaittu frekvenssi - odotettu frekvenssi).
Residuaalien perusteella huomaamme, että kokoomusta, vihreitä ja kristillisdemokraatteja äänestäneiden osuus on suurempi kuin odotettu, kun taas lähes kaikkien muiden puolueiden kohdalla se on pienempi. Toisessa taulukossa esitetään khii-toiseen -testisuureen arvo, vapausasteiden määrä sekä p-arvo. Esimerkin nollahypoteesi ei jää voimaan (p < 0.001), eli tutkimuspopulaation puoluekantajakauma eroaa tilastollisesti erittäin merkitsevästi eduskuntavaalien äänestysjakaumasta.
Kahden riippumattoman otoksen testit
Mann-Whitney, Kolmogorov-Smirnov Z, Moses, Wald-Wolfowitz
Kahden riippumattoman otoksen testeissä vertaillaan tutkittavan muuttujan arvoja ryhmittelymuuttujan määräämissä kahdessa ryhmässä. Hypoteesit ovat samankaltaiset kuin aiemmissa testeissä:
H0: Jakaumat ovat perusjoukossa samanlaiset
H1: Jakaumat ovat perusjoukossa erilaiset
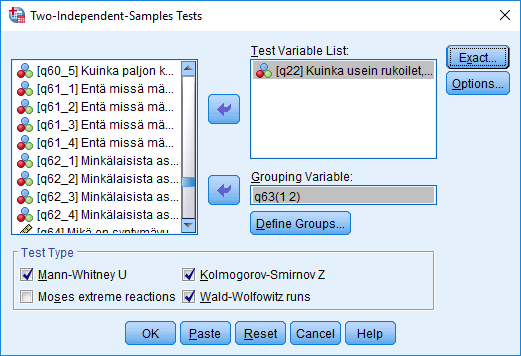
Tutkitaan European Values Study 2017 -esimerkkiaineiston muuttujien q22 'Kuinka usein rukoilet kirkollisia toimituksia lukuun ottamatta?' sekä q63 'Sukupuoli' avulla, ovatko rukoilutottumukset samanlaiset sukupuolten välillä. Ennen testiä tutkittavan muuttujan q22 vastausvaihtoehdot 8 'En osaa sanoa' ja 9 'Ei vastausta' sekä sukupuolimuuttujan arvot 8 ja 9 pitää luokitella puuttuvaksi tiedoksi (ks. muuttujamuunnoksia käsittelevät harjoitukset).
Valitse Analyze - Nonparametric Tests - Legacy Dialogs - 2 Independent Samples.... Siirrä avautuvassa ikkunassa muuttuja q22 Test Variable List: -kohtaan ja Grouping Variable: -kohtaan ryhmittelymuuttuja q63, jonka kahdella määrätyllä arvolla testi suoritetaan. Arvojen määrääminen tehdään napsauttamalla Define Groups... -painiketta. Test Type -kohdassa valitaan käytettävä testi. Mann-Whitney U-, Kolmogorov-Smirnov Z- ja Wald-Wolfowitz runs -testeillä tutkitaan, ovatko kaksi riippumatonta otosta samoin jakautuneesta perusjoukosta. Moses extreme reactions -testi on tarkoitettu lähinnä koeluontoisiin tutkimusasetelmiin, missä on olemassa selkeä kontrolli- sekä käsittelyryhmä.
Options -näppäintä painamalla voi valita tulostukseen lisää tunnuslukuja sekä valita puuttuvien tietojen käsittelyn. Jos analysoit havaintomäärältään pieniä aineistoja tai otosjakaumat ovat muodoltaan hyvin erilaisia, eksaktin testin käyttäminen on suositeltavaa. Voit valita sen Exact... -näppäimellä.
Ei-parametrisissa testeissä testisuureen laskemisessa ei käytetä alkuperäisiä havaintoarvoja. Alkuperäiset arvot korvataan järjestysluvuilla, pienin arvo saa järjestysluvun yksi, toiseksi pienin kaksi jne. Testisuureet lasketaan sitten näiden järjestyslukujen perusteella.
Suorita testit painamalla OK-näppäintä. Output-ikkunaan pitäisi tulostua kolmen testin tulokset, kuten kuvassa (tilan säästämiseksi kuvasta on poistettu Kolmogorovin-Smirnovin- ja Waldin-Wolfowitzin -testien yhteydessä tulostuvat frekvenssitaulukot).

Mann-Whitneyn U-testin tulostaulukossa raportoidaan aluksi järjestyslukujen (ranks) keskiarvot ja summat naisten ja miesten ryhmissä. Sekä keskiarvot että summat poikkeavat toisistaan melko paljon, mutta päätelläksemme, onko ero tilastollisesti merkitsevä vai vain sattuman vaikutusta, on tarkasteltava p-arvoa seuraavassa taulukossa. Taulukko antaa Mann-Whitneyn U:n, Wilcoxonin W:n sekä Z-testisuureen arvon. Suurempien otosten tapauksessa (> 20) ollaan lähinnä kiinnostuneita Z-testisuureen arvosta, joka on tässä tapauksessa -7,936. P-arvo < 0,001, joten nollahypoteesi hylätään yleisimmillä riskitasoilla.
Kolmogorovin-Smirnovin Z-testissä vertaillaan myös jakaumia toisiinsa (t-testien normaalisuusoletusten yhteydessä jakaumaa verrataan normaalijakaumaan). Tämä testi soveltuu hyvin pienemmille otoksille (< 25 havaintoa/ryhmä). Testissä tarkastellaan, onko jakaumien kertymäfunktioiden välinen ero merkitsevä. Testisuureen arvo on 3,762 ja p-arvo < 0,001, joten nollahypoteesi jakaumien samanlaisuudesta hylätään.
Waldin-Wolfowitzin testi on samankaltainen kuin Mann-Whitneyn U-testi, mutta järjestyslukujen sijaan siinä tarkastellaan järjestysluvuissa esiintyviä jaksoja. Jos jaksot esiintyvät ryhmissä satunnaisesti, niiden välillä ei ole eroa, mutta jos jaksot ovat säännönmukaisia, ryhmien voidaan olettaa eroavan toisistaan. Tämänkin testin tapauksessa p-arvo < 0,001, joten nollahypoteesi hylätään.
Testien perusteella rukoilutottumukset eroavat siis tutkimuspopulaatiossa miesten ja naisten välillä tilastollisesti erittäin merkitsevästi.
Usean riippumattoman otoksen testit
Kruskal-Wallis ja Median
Usean riippumattoman otoksen testeissä vertaillaan tutkittavan muuttujan jakaumia useamman kuin kaksiluokkaisen (k) ryhmittelymuuttujan luokissa. Testeillä tutkitaan, ovatko nämä k riippumatonta otosta samoin jakautuneesta perusjoukosta.
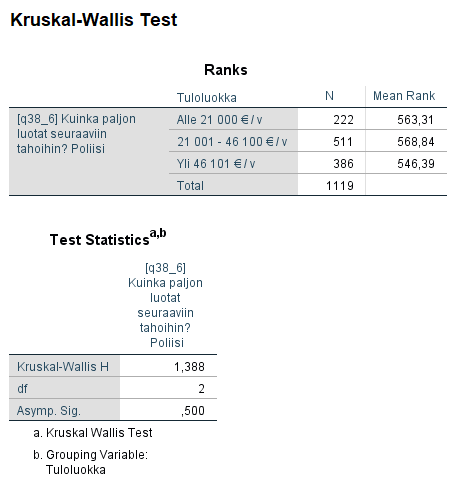
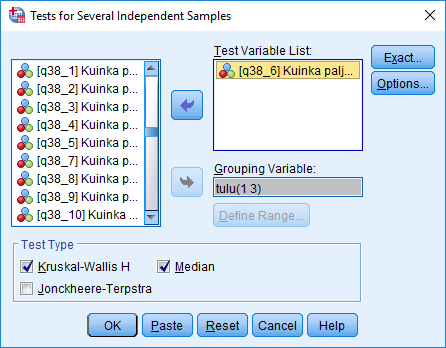
Tutkitaan European Values Study 2017 -esimerkkiaineiston muuttujien q98 'Mihin näistä tuloluokista perheesi kuuluu, kun kaikkien perheenjäsenten palkat, eläkkeet ja muut tulot lasketaan yhteen?' sekä q38_6 'Kuinka paljon luotat seuraaviin tahoihin? Poliisi' avulla, onko luottamus poliisiin samanlaista eri tuloluokissa.
Ensin uudelleenluokittelemme muuttujan q38_6 arvot 8 'En osaa sanoa' ja 9 'Ei vastausta' puuttuvaksi tiedoksi (ks. muuttujamuunnoksia käsittelevät harjoitukset). Seuraavaksi muodostamme muuttujasta q98 uuden muuttujan
tulu,
johon uudelleenluokittelemme tuloluokat seuraavasti:
1, 2, 3 -> 'Alle 21 000 €/v'
4, 5, 6, 7 -> '21 001 - 46 100 €/v'
8, 9, 10 -> 'Yli 46 100 €/v'
Valitse sitten Analyze - Nonparametric Tests - Legacy Dialogs - K Independent Samples... . Siirrä avautuvassa ikkunassa muuttuja q38_6 Test Variable List: -kohtaan ja Grouping Variable -kohtaan ryhmittelymuuttuja tulu, jonka ryhmissä testi suoritetaan. Arvojen määrääminen tehdään napsauttamalla Define Range... -painiketta ja kirjoittamalla sinne tulu-muuttujan minimi- ja maksimiarvot 1 ja 3. Test Type -kohdassa valitaan käytettävä testi. Kruskal-Wallis H -testi on Mann-Whitney -testin yleistys ja sitä voidaan käyttää ei-parametrisena vastineena yksisuuntaiselle varianssianalyysille. Median-testissä aineisto jaetaan kussakin ryhmässä mediaania suurempiin ja pienempiin havaintoihin ja testataan, onko ryhmien välillä riippuvuutta.
Options-näppäintä painamalla voi valita tulostukseen lisää tilastollisia tunnuslukuja sekä valita puuttuvien tietojen käsittelyn. Jos analysoit havaintomäärältään pieniä aineistoja tai otosjakaumat ovat muodoltaan hyvin erilaisia, eksaktin testin käyttäminen on suositeltavaa. Voit valita sen Exact... -näppäimellä.
Suorita testit painamalla OK-näppäintä. Tulostaulukot tulostuvat tulosikkunaan. Kruskal-Wallis H -testissä näemme, kuten Mann-Whitneyn U-testissä, järjestyslukujen keskiarvot tarkasteltavissa ryhmissä. Saamme p-arvoksi 0,500, joten nollahypoteesi jää voimaan. Median -testissä ylempi tulostaulukko listaa havaintojen määrät mediaanin ala- ja yläpuolella tarkasteltavissa ryhmissä. Erot eivät näytä suurilta ja p-arvon (0,227) perusteella nollahypoteesi jää voimaan. Erot luottamuksessa poliisiin eri perheen tuloluokissa eivät ole tilastollisesti merkitseviä.