Korrelaatiokertoimet - SPSS-harjoitus 1
Jos olet ensimmäistä kertaa aloittamassa SPSS-harjoitusta, on ennen varsinaisen harjoituksen tekemistä syytä tutustua opiskeluohjeisiin.
Voit harjoitella korrelaatiokertoimen laskemista oheisen videon avulla, jossa käytetään European Social Survey 2012 -kyselyn Suomen aineistoa.
Voit myös harjoitella korrelaatiokertoimen ja riippuvuuslukujen laskemista seuraamalla alla olevia ohjeita, joissa käytetään Maailmanpankin -tilastoista koottua aineistoa (ks. aineiston kuvaus).
Havaintoaineiston hakemisesta SPSS-ohjelmaan on erilliset ohjeet.
Korrelaatiokertoimet jatkuville muuttujille

Pearsonin korrelaatiokertoimen laskemisen oletuksina on, että muuttujat ovat jatkuvia, niiden välinen yhteys on lineaarista ja ne ovat jotakuinkin normaalisti jakautuneita. Muuttujilla ei myöskään tulisi olla merkittävästi poikkeavia havaintoja. Hajontakuviosta voi tarkistaa, onko muuttujien välinen riippuvuus lineaarista. Normaalijakautuneisuuden testillä voi puolestaan testata muuttujien normaalisuutta. Hajontakuviosta näkyvät myös yksittäiset poikkeavat havainnot, jotka saattavat vaikuttaa huomattavasti korrelaatiokertoimen arvoon. Kokeile myöhemmin poistaa aineistosta selkeästi poikkeavia arvoja ja huomaat, kuinka se vaikuttaa korrelaatiokertoimen arvoon.
SPSS ohjelmistossa korrelaatiokertoimien laskenta aloitetaan valikosta Analyze - Correlate - Bivariate...
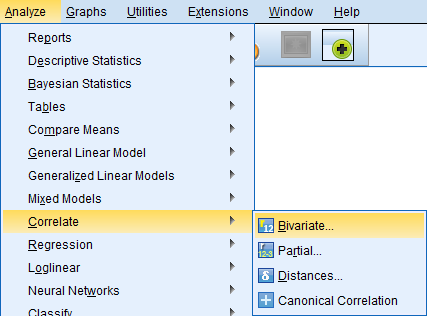
Lasketaan aineistosta jatkuvien muuttujien lukutaidottomien osuus väestöstä (V18) ja elinajanodote (V27) välinen Pearsonin korrelaatiokerroin. Oletetaan tässä esimerkin vuoksi, että muuttujat ovat normaalisti jakautuneita.
Muuttujat valitaan Variables -laatikkoon. Muuttujia voi lisätä enemmänkin kuin kaksi, jolloin ohjelma laskee kaikki muuttujien väliset korrelaatiot. Merkitsevyystesteistä on mahdollista valita kaksi- tai yksisuuntaiset testit.
Options -painikkeen takaa löytyvät vaihtoehdot puuttuvien tietojen käsittelyyn sekä muuttujakohtaisten keskiarvojen ja -virheiden tulostukseen. Myös ristitulopoikkeamat sekä kovarianssit voi halutessaan tulostaa. Pidetään tässä tapauksessa oletusvalinnat.
Lopuksi painetaan Continue ja OK ja saadaan tulokset.
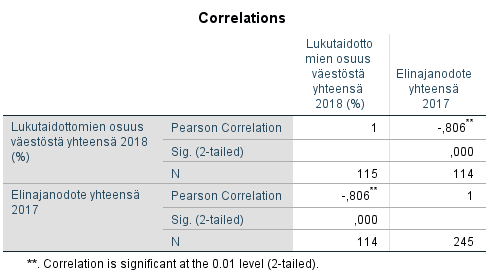
Correlations -taulusta nähdään, että muuttujien välinen korrelaatio on -0,806 ja se on merkitsevä merkitsevyystasolla 0,01. Näyttää siis siltä, että muuttujien välillä on vahva negatiivinen korrelaatio. Lukutaidottomien osuuden ollessa pienempi, elinajanodote on korkeampi ja päinvastoin. Huomattavaa on, että korrelaatiokertoimen avulla ei voi selittää riippuvuuden suuntaa eli vaikuttaako lukutaidottomuus elinajanodotteeseen vai toisinpäin. Korrelaatiokerroin ei myöskään kerro kausaalisuudesta tai siitä, onko yhteyden taustalla muita tekijöitä (ks. myös luku kausaalipäättelystä). Kausaalisuuden suunta on pääteltävä muulla tavoin tai sitä voidaan tutkia muillakin analyyseillä (esim. regressioanalyysi).
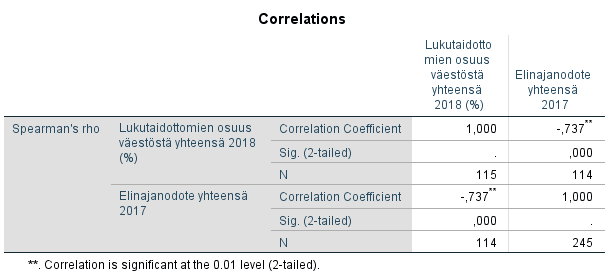
Jos Pearsonin korrelaatiokertoimen laskemiselle asetetut parametriset oletukset (muuttujien normaalijakautuneisuus, ei poikkeavia havaintoja) eivät täyty, voidaan käyttää Spearmanin tai Kendallin järjestyskorrelaatiokerrointa. Ne lasketaan SPSS:llä kuten Pearsonin korrelaatiokerroin, mutta Correlation Coefficients -kohdasta valitaan Spearman ja Kendall's tau-b. Edellisessä esimerkissä käytetyille muuttujille laskettu Spearmanin korrelaatiokerroin on -0,737 ja se on merkitsevä merkitsevyystasolla 0,01.
Riippuvuusluvut järjestysasteikollisille muuttujille
Seuraavaksi laskemme riippuvuuslukuja järjestysasteikollisille muuttujille. Edellä mainittuja Spearmanin sekä Kendallin korrelaatiokerrointa voidaan käyttää myös järjestysasteikollisille muuttujille. Lisäksi voidaan käyttää ainoastaan järjestysasteikollisille muuttujille tarkoitettuja Gammaa tai Somersin deltaa, jotka sopivat tiettyihin erityistilanteisiin.
Käytetään tässä esimerkissä muuttujina maan bruttokansantuloa (V6), jossa maat ja alueet on luokiteltu neljään ryhmään sekä luokiteltua elinajanodotemuuttujaa. Uudelleen koodataan elinajanodote kolmeluokkaiseksi (alle 70, 70–80 ja yli 80) (ks. tarvittaessa muuttujien muunnoksia käsittelevät harjoitukset).
Spearmanin ja Kendallin korrelaatiokertoimet voidaan laskea samasta valikosta kuin Pearsonin: Analyze - Correlate - Bivariate...
Myös tulokset tulkitaan samalla tavalla.
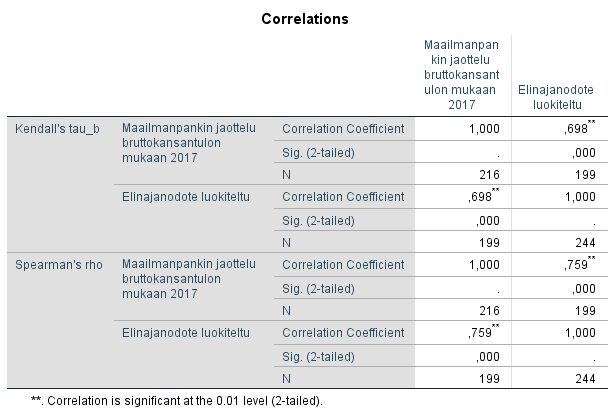
Sekä Kendallin että Spearmanin korrelaatiokertoimen kohdalla korrelaatio on merkitsevä merkitsevyystasolla 0,01. Arvot ovat molemmissa tapauksissa positiiviset ja melko korkeat (0,698 ja 0,759), joten korkeampi bruttokansantulo korreloi korkeamman elinajanodotteen kanssa. Erot kertoimen arvossa johtuvat niiden erilaisista laskutavoista. Kendallin tau-b on hyödyllinen erityisesti pienillä otoksilla ja silloin, kun havaintoja suuruusjärjestykseen asetettaessa esiintyy paljon yhtä suuria järjestyslukuja. Kendallin tau-b:tä tulisi käyttää tapauksissa, jossa tarkasteltujen muuttujien asteikot ovat yhtä suuria. Koska muuttujissamme on eri määrä arvoja (kolme ja neljä), olisi oikeastaan syytä tarkastella Kendallin tau-c:n arvoa (ks. alla).
Järjestysasteikollisille muuttujille voidaan laskea myös Gamma, Somersin delta ja Kendallin tau-c. Kuten Kendallin järjestyskorrelaatiokerrointa (tau-b), myös gammaa käytetään yleensä tapauksissa, joissa havaintoja suuruusjärjestykseen asetettaessa esiintyy paljon yhtä suuria järjestyslukuja. Somersin delta soveltuu tilanteisiin, joissa tiedetään selittävä ja selitettävä muuttuja ja halutaan tarkastella korrelaatiota tiettyyn suuntaan. Kendallin tau-c on puolestaan Kendallin korrelaatiokertoimen muoto, joka sopii erityisesti tapauksiin, joissa tarkasteltavien muuttujien asteikot ovat erimitalliset.
Näiden lukujen laskeminen onnistuu tekemällä muuttujista ristiintaulukko (Analyze - Descriptive Statistics - Crosstabs...) ja valitsemalla Statistics -painikkeella nämä riippuvuusluvut.
Painamalla Continue ja OK saadaan tulokset.
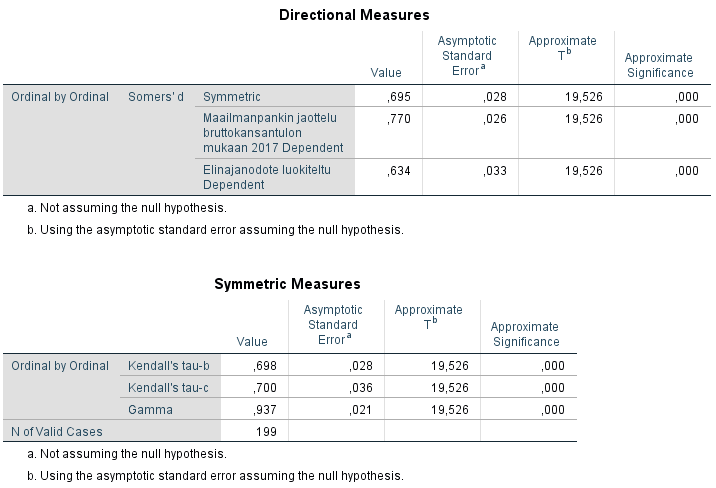
Somersin deltan tulokset esitetään Directional Measures -taulukossa. Jos oletetaan, että bruttokansantulo on elinajanodotetta selittävä tekijä, katsotaan alinta riviä, jolla elinajanodote on riippuva muuttuja. Value-sarake kertoo kertoimen arvon, joka on 0,634. Approximate Significance -sarake kertoo tilastollisesta merkitsevyydestä, ja tässä tapauksessa korrelaatio on merkitsevä 0,01 merkitsevyystasolla.
Symmetric Measures -taulukosta tulkitaan tulokset samalla tavalla. Kendallin tau-c saa arvoksi 0,7 ja gamma peräti 0,937. Korrelaatiot ovat merkitseviä merkitsevyystasolla 0,01.
Riippuvuusluvut luokitteluasteikollisille muuttujille
Luokitteluasteikollisille muuttujille voi niin ikään laskea useita riippuvuuslukuja. Lasketaan riippuvuusluvut sille, kuuluuko maa vähiten kehittyneisiin valtioihin vai ei (V5) ja edellisessä esimerkissä luodulle luokitellulle elinajanodotemuuttujalle.
Tehdään muuttujista jälleen ristiintaulukko (Analyze - Descriptive Statistics - Crosstabs...) ja valitaan Statistics -painikkeella Nominal-kohdasta riippuvuusluvut luokitteluasteikollisille muuttujille.
Painamalla Continue ja OK saadaan tulokset.
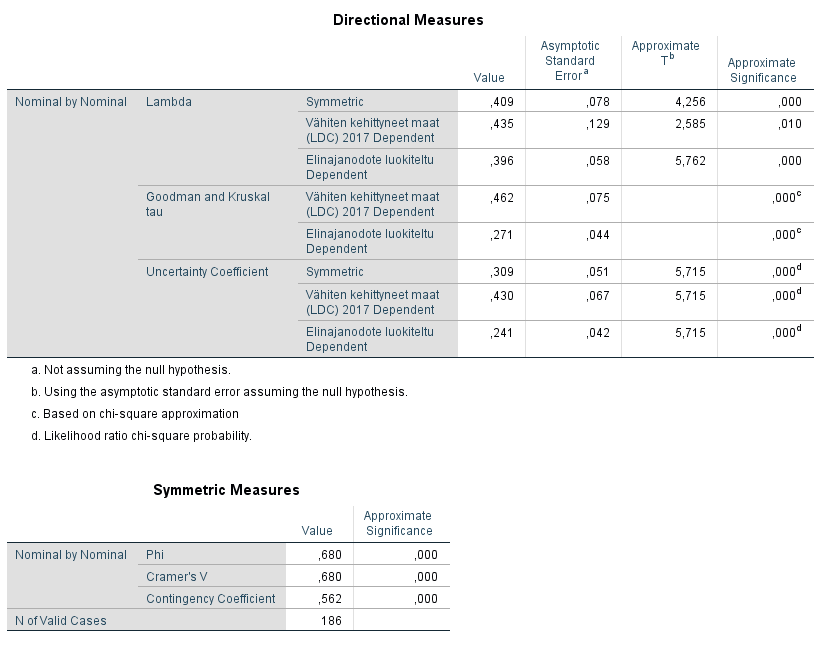
Tulokset kertovat rivi- ja sarakemuuttujan välisestä yhteydestä. Directional Measures -taulukossa tarkastellaan muuttujia sen mukaan, kumpaa pidetään selittäjänä ja kumpaa selitettävänä. Tässä tapauksessa voidaan olettaa kuulumisen vähemmän kehittyneisiin maihin selittävän elinajanodotetta, jolloin elinajanodote on riippuva muuttujamme. Siksi tarkastellaan alempaa riviä.
Lambdan, Goodmanin ja Kruskalin taun ja epävarmuuskertoimen (uncertainty coefficient) arvot kertovat siitä, kuinka hyvin selitettävä muuttuja ennustaa selittävän muuttujan vaihtelua. Arvo 0 tarkoittaa, että selittävä muuttuja ei ennusta vaihtelua lainkaan ja 1 tarkoittaa, että selittävä muuttuja ennustaa vaihtelun täydellisesti. Erot arvoissa johtuvat lukujen erilaisista laskutavoista, joita ei käsitellä tässä tarkemmin. Arvot voidaan muuttaa tulkinnassa prosenttiluvuksi (esim. epävarmuuskertoimen kohdalla 24,1 %) ja sanoa, että tieto selittävästä muuttujastamme parantaa selitettävän muuttujamme ennustettavuutta 24,1 prosentilla.
Symmetric Measures -taulukosta voidaan tulkita Cramerin V ja kontingenssikerroin, jotka perustuvat khiin neliöön. Myös nämä saavat arvoja nollan ja yhden väliltä, ja arvot lähempänä yhtä kertovat vahvemmasta yhteydestä. Arvon 0,3 ylittävät arvot kertovat usein jo vahvasta yhteydestä, joten voidaan sanoa, että tarkastelemiemme muuttujien välillä on vahva riippuvuus.
Approximate Significance -sarake kertoo tilastollisesta merkitsevyydestä ja tässäkin tapauksessa riippuvuus on tilastollisesti merkitsevää 0,01 merkitsevyystasolla.